ENTERPRISE INTEGRATION PATTERNS IN MULE
Herding the messages
If you thought things couldn't get any better than last week's Splitter, buckle up your middleware, we're heading on to the next stage of our look at Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf.
After splitting our shipment into byte sized packages, someone has to clean up this logistical nightmare and put it all back together again. Cue The Aggregator and how this can be implemented by MuleSoft.
The Aggregrator
“How do we combine the results of individual but related messages so they can be processed as a whole?”
Use a stateful filter, an Aggregator, to collect and store individual messages until a complete set of related messages has been received. Then, the Aggregator publishes a single message distilled from the individual messages.

Continuing our shipment and packages use-case, our next task is to re-assemble these transformed and potentially enriched messages back into a coherent shipment message. The aggregator pattern serves this exact purpose, collecting all the pieces to form a complete, aggregated message once all the individual parts have been processed.
It is important that an aggregator does the following:
Defines a coherent aggregation strategy
This strategy outlines how the messages are combined. For instance, you might aggregate JSON payloads by merging them into a single JSON object where each key represents a package.
Specifies a correlation ID
Continue using the shipment number as the correlation ID, ensuring all messages related to the same shipment are aggregated together.
Sets completion criteria
You can define the criteria for when the aggregation is complete, such as receiving all package messages or a timeout period elapsing.
This is The (MuleSoft) Way
For our shipment, each package that has been split must be formatted into a json object and enriched with tax and delivery options and then reformed into the shipment.
Below we can see the main flow in this super real life scenario (hmm) where we have a list of package IDs that are going to be split and processed.
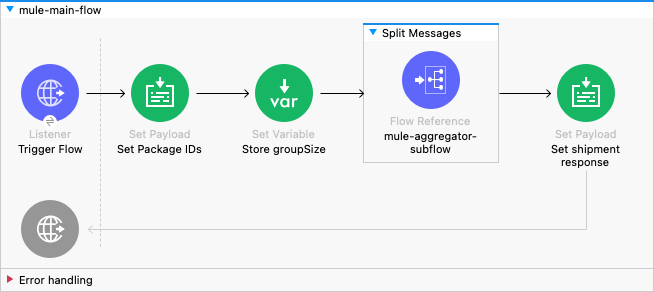

Each package is sent to the mule-aggregator-subflow where the transformation, enrichment and aggregation will occur.
The group based aggregator fulfils two of the required criteria for the aggregator pattern. It specifies a correlation ID and sets completion criteria.
The correlation ID uses the default mechanism provided by MuleSoft and is propagated in the for-each block. However, the Shipment ID would also be a suitable candidate.
The completion criteria is established by group size which is set in a variable early in the main flow and referenced by the aggregator.

Each package is enriched with nonsensical information, as is the way of all contrived examples.

The last criteria of the aggregator is that it defines a coherent aggregation strategy. Here on 'Aggregation Complete' we include the original shipment ID as well as the aggregated items via payload.package

This outputs the payload similar to the following:

Until next time
A key feature of the aggregator pattern is its ability to keep tabs on each cluster of related messages, and Mule elegantly handles this with its robust Object Store.
In the coming weeks, we’ll dive into the Scatter-Gather pattern, exploring both the Distribution and Auction style variants and their implementation in Mule. Pay special attention to the Auction style, where the use of the Object Store and Mule aggregator truly shines, but let's not get ahead of ourselves.
Just like the aggregator, things are coming together nicely...
By the way...
The Mule source code that accompanies this blog is available here. You're welcome.
